
Very often, it’s common for individuals to perceive a High-Performance Computing (HPC) setup as if it were a singular, extraordinary device. There are instances when users might even believe that the terminal they are accessing represents the full extent of the computing network. So, what exactly constitutes an HPC system?
What is an HPC (High-Performance Computing) Cluster?
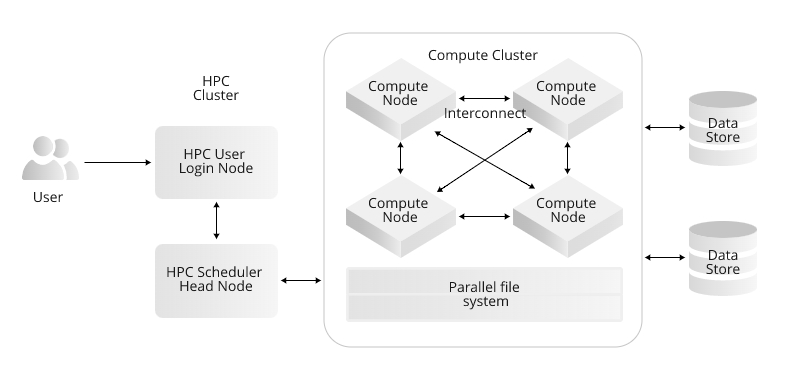
An High-Performance Computing (HPC) cluster is a type of computer cluster specifically designed and assembled for delivering high levels of performance that can handle compute-intensive tasks. An HPC cluster is typically used for running advanced simulations, scientific computations, and big data analytics where single computers are incapable of processing such complex data or at speeds that meet the user requirements. Here are the essential characteristics of an HPC cluster:
Components of an HPC Cluster
- Compute Nodes: These are individual servers that perform the cluster’s processing tasks. Each compute node contains one or more processors (CPUs), which might be multi-core; memory (RAM); storage space; and network connectivity.
- Head Node: Often, there’s a front-end node that serves as the point of interaction for users, handling job scheduling, management, and administration tasks.
- Network Fabric: High-speed interconnects like InfiniBand or 10 Gigabit Ethernet are used to enable fast communication between nodes within the cluster.
- Storage Systems: HPC clusters generally have shared storage systems that provide high-speed and often redundant access to large amounts of data. The storage can be directly attached (DAS), network-attached (NAS), or part of a storage area network (SAN).
- Job Scheduler: Software such as Slurm or PBS Pro to manage the workload, allocating compute resources to various jobs, optimizing the use of the cluster, and queuing systems for job processing.
- Software Stack: This may include cluster management software, compilers, libraries, and applications optimized for parallel processing.
Functionality
HPC clusters are designed for parallel computing. They use a distributed processing architecture in which a single task is divided into many sub-tasks that are solved simultaneously (in parallel) by different processors. The results of these sub-tasks are then combined to form the final output.
HPC Cluster Characteristics
An HPC data center differs from a standard data center in several foundational aspects that allow it to meet the demands of HPC applications:
- High Throughput Networking
HPC applications often involve redistributing vast amounts of data across many nodes in a cluster. To accomplish this effectively, HPC data centers use high-speed interconnects, such as InfiniBand or high-gigabit Ethernet, with low latency and high bandwidth to ensure rapid communication between servers.
- Advanced Cooling Systems
The high-density computing clusters in HPC environments generate a significant amount of heat. To keep the hardware at optimal temperatures for reliable operation, advanced cooling techniques — like liquid cooling or immersion cooling — are often employed.
- Enhanced Power Infrastructure
The energy demands of an HPC data center are immense. To ensure uninterrupted power supply and operation, these data centers are equipped with robust electrical systems, including backup generators and redundant power distribution units.
- Scalable Storage Systems
HPC requires fast and scalable storage solutions to provide quick access to vast quantities of data. This means employing high-performance file systems and storage hardware, such as solid-state drives (SSDs), complemented by hierarchical storage management for efficiency.
- Optimized Architectures
System architecture in HPC data centers is optimized for parallel processing, with many-core processors or accelerators such as GPUs (graphics processing units) and FPGAs (field-programmable gate arrays), which are designed to handle specific workloads effectively.
Applications of HPC Cluster
HPC clusters are used in various fields that require massive computational capabilities, such as:
- Weather Forecasting
- Climate Research
- Molecular Modeling
- Physical Simulations (such as those for nuclear and astrophysical phenomena)
- Cryptanalysis
- Complex Data Analysis
- Machine Learning and AI Training
Clusters provide a cost-effective way to gain high-performance computing capabilities, as they leverage the collective power of many individual computers, which can be cheaper and more scalable than acquiring a single supercomputer. They are used by universities, research institutions, and businesses that require high-end computing resources.
Summary of HPC Clusters
In conclusion, this comprehensive guide has delved into the intricacies of High-Performance Computing (HPC) clusters, shedding light on their fundamental characteristics and components. HPC clusters, designed for parallel processing and distributed computing, stand as formidable infrastructures capable of tackling complex computational tasks with unprecedented speed and efficiency.
At the core of an HPC cluster are its nodes, interconnected through high-speed networks to facilitate seamless communication. The emphasis on parallel processing and scalability allows HPC clusters to adapt dynamically to evolving computational demands, making them versatile tools for a wide array of applications.
Key components such as specialized hardware, high-performance storage, and efficient cluster management software contribute to the robustness of HPC clusters. The careful consideration of cooling infrastructure and power efficiency highlights the challenges associated with harnessing the immense computational power these clusters provide.
From scientific simulations and numerical modeling to data analytics and machine learning, HPC clusters play a pivotal role in advancing research and decision-making across diverse domains. Their ability to process vast datasets and execute parallelized computations positions them as indispensable tools in the quest for innovation and discovery.